« Pas d’Intelligence sans Apprentissage »

Par Chaima Ghanjati, Rosalie Rouphael, Saifeddine Rjiba, Mohamed Alkoussa dit Albacha.
Yann LeCun présentait le 4 février 2016 «l’apprentissage profond : une révolution en IA» lors de sa leçon inaugurale au Collège de France. Il était durant cette année détenteur de la Chaire informatique et sciences numériques.
Lancé en 2010, le Défi de reconnaissance visuelle à grande échelle (ILSVRC) est une compétition annuelle où la communauté de recherche concoure pour développer un algorithme de détection d’objets et de classification d’images. La première édition a obtenu une précision de 72 % de reconnaissance d’images : ce résultat était remarquable. En 2012, un grand record de 88 % est atteint ! C’était une véritable révolution technique de l’Intelligence Artificielle, cette transition a été induite par Alex Krizhevsky de l’université de Toronto, qui a travaillé avec les réseaux de neurones à convolution profonde, connue sous le nom de ConvNet. Cette technique de Deep Learning (DL) a été introduite par Yann LeCun, ce qui lui a permis d’obtenir les meilleurs résultats sur les tâches de classification d’images en termes de précision. Ces résultats ont suscité un intérêt pour l’apprentissage en profondeur dans le Machine Learning. Ainsi, on peut dire que malgré son explosion en 2012, l’IA existe depuis 1980, dont l’un de ses parrains est Yann LeCun, détenteur de la Chaire informatique et sciences numériques du Collège de France en 2016.

Il est l’un des plus éminents chercheurs en IA, apprentissage machine, vision artificielle et robotique. Il était jusqu’en janvier 2018, directeur du laboratoire de recherche en IA de Facebook.
Dans sa leçon inaugurale, LeCun a abordé plusieurs points : la légitimité de s’inspirer de la manière dont fonctionne le cerveau humain pour fabriquer des machines intelligentes auto-apprenantes et évolutives ; les différents types d’apprentissage automatique et le Deep Learning.
En recherche, une vraie question se pose : est-il possible que l’IA arrive à s’auto-améliorer d’elle-même ? LeCun rappelle que la loi de Moore est une loi informatique empirique admise depuis 1970. Sa version simplifiée énonce que la vitesse du processeur ou la puissance de traitement globale des ordinateurs doublera tous les deux ans et estime qu’on parviendra à la capacité du cerveau humain en 2045.
À cette question, les premiers avis exploitaient le lien entre la biologie et l’IA, sachant que la solution n’est pas d’imiter la biologie dans ses moindres détails mais de s’en inspirer ; à titre d’exemple l’avion III du français Clément Ader en 1897, très proche physiquement de la chauve-souris, n’était pas une réussite.
La notion d’apprentissage est le cœur de l’innovation de l’IA : c’est la capacité de mettre à jour en continu les poids des données d’entrainement de l’algorithme. Néanmoins, cette technique nécessite une grande capacité de calcul et des bases de données massives. Des telles ressources n’étaient pas disponibles jusqu’à l’arrivée des cartes graphique NVIDIA et des bases de données comme ImageNet au début de l’année 2010. C’est à partir de ce moment que l’apprentissage automatique a été révolutionné !

À noter que le Machine Learning est une technique de l’IA qui permet aux ordinateurs d’apprendre et prédire sans être programmés explicitement. Une première distinction à faire en Machine Learning est la différence entre les trois types d’apprentissage automatique : supervisé, non-supervisé et par renforcement.
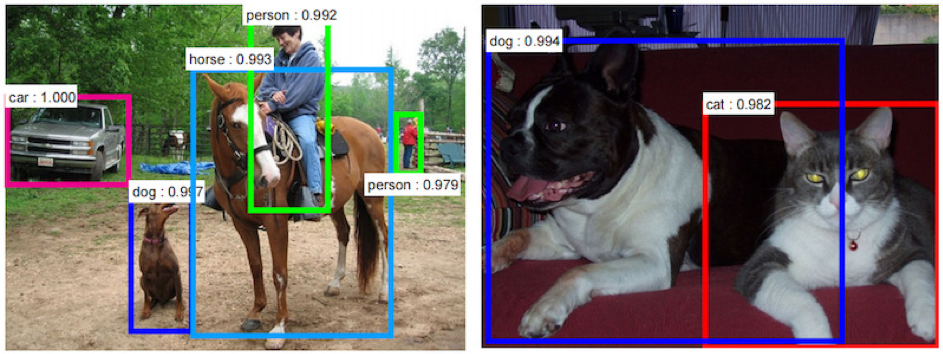
En apprentissage supervisé, on apprend à l’algorithme à prédire une classe cible pour des données non annotées, à partir de données d’entrées annotées. Pour bien comprendre, l’exemple de la classification d’objets a été traité.
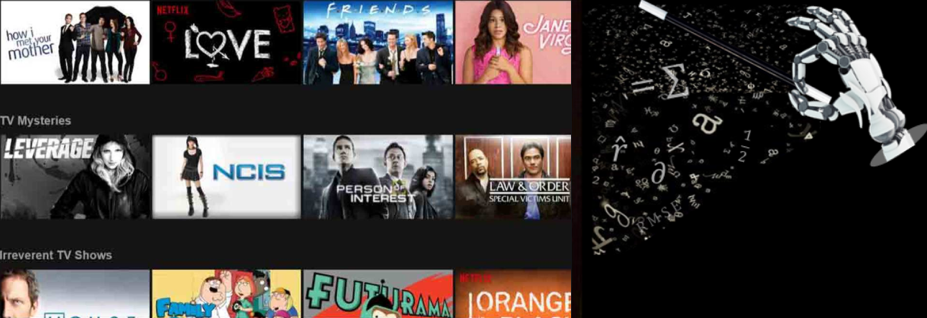
En apprentissage non-supervisé, les données d’entrées ne sont pas annotées. Ainsi, l’algorithme peut seulement regrouper les données suivant des similarités et des caractéristiques communes. Un système de recommandation de films est un exemple d’apprentissage non supervisé.
L’apprentissage par renforcement consiste à apprendre à l’algorithme les actions à faire, à partir d’expériences successives, afin d’optimiser la solution. Les jeux vidéo, jeux de go et d’échecs utilisent l’apprentissage par renforcement.

L’apprentissage profond ou le Deep Learning est une évolution de l’apprentissage automatique ou Machine Learning qui fonctionne comme un réseau de neurones inspiré du fonctionnement du cerveau. Ce réseau est une structure utilisée pour combiner un ensemble d’algorithmes informatiques simples dans le but de résoudre une tache spécifique. Il est composé de plusieurs couches liées, chacune contenant des neurones artificiels connectés à travers des synapses afin de transmettre des signaux.
Pour faire la différence entre le Machine Learning et le Deep Learning, il faut distinguer les outils utilisés et les types de données traités : si on recourt à des ConvNet, alors il s’agit d’un modèle algorithmique profond qui utilise plusieurs couches pour traiter des images ou des séries temporelles alors que les algorithmes simples de ML sont formés par une seule couche et traitent seulement les types de données structurées.
Les domaines d’applications de l’IA est très large : la détection et la reconnaissance des images, la reconnaissance vocale, le traitement automatique du langage naturel, la légende automatique des images et la génération artificielle des images.
Une machine qui voit ? Il y a quelques années c’était incroyable. Quel pourrait être l’étape suivante ? La machine pourrait un jour détecter un cancer, des maladies cardiovasculaires, des consommations de drogues… En effet, les applications potentielles sont immenses, allant de l’analyse de données médicales aux voitures autonomes. L’ordinateur ne se contente donc plus de classifier, il “imagine”. Cette action d’imaginer serait un élément central dans le futur de la recherche. En revanche, l’apprentissage profond, plein de promesses pour l’humanité, recèle-t-il aussi d’importants dangers ? La violation de la vie privée par les réseaux sociaux, le contrôle social, les armes de guerre, le chômage… sont uniquement des menaces si les techniques de l’IA sont mal utilisées.
L’intelligence de l’ordinateur augmente grâce à l’apprentissage profond qui «est inhérent à l’intelligence» mais le critère d’humanité ne peut pas être reproduit ou appris «l’intelligence humaine est autant sociale que personnelle».
Vidéo de la conférence inaugurale au Collègue de France par Yann LeCun.
Cet article a été réalisé dans le cadre d’une formation à l’écriture journalistique avec l’École doctorale Sciences et ingénierie des systèmes, mathématiques, informatiques (Sismi) des universités de Poitiers et Limoges.
Auteurs
Chaima Ghanjati est ingénieure en mécatronique en préparation de thèse en co-tutelle (Tunisie-France) en génie électrique, en collaboration avec l’université de Poitiers-École national supérieure d’ingénieurs de Poitiers-Laboratoire d’informatique et d’automatique pour les systèmes (Lias) et l’université de Tunis-École national supérieure d’ingénieurs de Tunis-Laboratoire des systèmes électriques (LSE). La thèse porte sur l’optimisation et le contrôle des réseaux multi-sources intégrant énergies renouvelables et systèmes de stockage d’énergie.
Rosalie Rouphael est ingénieure en génie électrique en préparation de thèse au sein de l’université de Poitiers-École national supérieure d’ingénieurs de Poitiers-Laboratoire d’informatique et d’automatique pour les systèmes (Lias). La thèse porte sur l’optimisation d’une architecture et gestion de flux énergétique d’un micro-réseau.
Saifeddine Rjiba est ingénieur polytechnicien en préparation de thèse CIFRE au sein de l’université de Poitiers (XLIM) en collaboration avec Canon medical systems France. La thèse porte sur l’assistance virtuelle pour la prévention des risques cardiovasculaires.
Mohamed Alkoussa dit Albacha est doctorant en génie électrique au sein de l’université de Poitiers-École national supérieure d’ingénieurs de Poitiers-Laboratoire d’informatique et d’automatique pour les systèmes (Lias). La thèse porte sur la caractérisation des systèmes en régime non stationnaires : modélisation en vue du contrôle et du diagnostic.






